1. Add a test
Each new feature begins with writing a test.
2. Run all tests and see the new one fail
This validates that the new test does not mistakenly pass without requiring any new code. The new test should also fail for the expected reason. This step ensures the test will require the right behavior: it tests the test itself, in the negative.
3. Write some code
The next step is to write some code that will pass the new test.
4. Run the automated tests and see them succeed
5. Refactor code
Now the code can be cleaned up as necessary. By re-running the test cases the developer can be confident that refactoring is not damaging any existing functionality. The concept of removing duplication is an important aspect of any software design. In this case, however, it also applies to removing any duplication between the test code and the production code.
Monday, January 22, 2007
Boxing and unboxing in C#
Boxing and unboxing is an essential concept in C#. With Boxing and unboxing one can link between value-types and reference-types by allowing any value of a value-type to be converted to and from type object. Boxing and unboxing enables a unified view wherein a value of any type can ultimately be treated as an object. Converting a value type to reference type is called Boxing. Unboxing is an explicit operation.
C# provides a unified type system. All types including value types derive from the type object. It is possible to call object methods on any value, even values of primitive types such as int.
Example:
class Test
{
static void Main() {
Console.WriteLine(3.ToString());
}
}
class Test
{
static void Main() {
int i = 1;
object o = i; // boxing
int j = (int) o; // unboxing
}
}
The above example shows both boxing and unboxing. When a variable of a value type needs to be converted to a reference type, an object box is allocated to hold the value, and the value is copied into the box. A boxing conversion permits any value-type to be implicitly converted to the type object or to any interface-type implemented by the value-type. Boxing a value of a value-type consists of allocating an object instance and copying the value-type value into that instance.
Unboxing is just the opposite. When an object box is cast back to its original value type, the value is copied out of the box and into the appropriate storage location.
C# provides a unified type system. All types including value types derive from the type object. It is possible to call object methods on any value, even values of primitive types such as int.
Example:
class Test
{
static void Main() {
Console.WriteLine(3.ToString());
}
}
class Test
{
static void Main() {
int i = 1;
object o = i; // boxing
int j = (int) o; // unboxing
}
}
The above example shows both boxing and unboxing. When a variable of a value type needs to be converted to a reference type, an object box is allocated to hold the value, and the value is copied into the box. A boxing conversion permits any value-type to be implicitly converted to the type object or to any interface-type implemented by the value-type. Boxing a value of a value-type consists of allocating an object instance and copying the value-type value into that instance.
Unboxing is just the opposite. When an object box is cast back to its original value type, the value is copied out of the box and into the appropriate storage location.
Mutex
A MUTEX is a mutual exclusion algorithms used in concurrent programming to avoid the simultaneous use of a common resource, such as a global variable, by pieces of computer code called critical sections.
Examples of such resources are flags, counters or queues, used to communicate between code that runs concurrently, such as an application and its interrupt handlers. The problem is acute because a thread can be stopped or started at any time.
A mutex is also a common name for a program object that negotiates mutual exclusion among threads, also called a lock.
Examples of such resources are flags, counters or queues, used to communicate between code that runs concurrently, such as an application and its interrupt handlers. The problem is acute because a thread can be stopped or started at any time.
A mutex is also a common name for a program object that negotiates mutual exclusion among threads, also called a lock.
Saturday, January 20, 2007
Tuesday, January 16, 2007
Hofstadter's law
A very interesting adage. I'm not sure how you pronounce the guy's name but the saying goes like this:
It always takes longer than you expect, even when you take into account Hofstadter's Law.
Do you see the recursion in it? This is a self-referencing adage by Douglas Hofstadter. It is often cited among programmers, especially in discussions of techniques to improve productivity. Hofstadter's Law is a profound statement of the difficulty of accurately estimating the amount of time it will take to complete tasks of any substantial complexity.
Even after you have taken Hofstadter's Law into account, by Hofstadter's Law you must still take Hofstadter's Law into account, and this remains true no matter how many times you have already applied Hofstadter's Law.
It is therefore impossible to ever fully take Hofstadter's Law into account, at least in finite time. While some recursive functions do seem to eventually converge on an approximate solution (e.g., x/2 approaches zero when its output is repeatedly fed back into it), anyone who has attempted to manage a software project can testify that this does not seem to be true of Hofstadter's Law; if anything, estimates that take Hofstadter's Law into account even partially seem to have an infinite, or at least very large, upper bound. Thus, Hofstadter's Law implies that it is not merely difficult to estimate a project—it is potentially infinitely difficult
A (somewhat joking) rule of thumb introduced by Hofstadter for calculating an approximate time is to double the number and step up to the next higher units. For example, a job estimated at 1 hour can be accomplished in 2 days, while a 3-month project will take you 6 years.
PS: finite difficulty: requires that the extra difficulty decrease quickly enough for the recursive series to converge to a finite value in finite time).
It always takes longer than you expect, even when you take into account Hofstadter's Law.
Do you see the recursion in it? This is a self-referencing adage by Douglas Hofstadter. It is often cited among programmers, especially in discussions of techniques to improve productivity. Hofstadter's Law is a profound statement of the difficulty of accurately estimating the amount of time it will take to complete tasks of any substantial complexity.
Even after you have taken Hofstadter's Law into account, by Hofstadter's Law you must still take Hofstadter's Law into account, and this remains true no matter how many times you have already applied Hofstadter's Law.
It is therefore impossible to ever fully take Hofstadter's Law into account, at least in finite time. While some recursive functions do seem to eventually converge on an approximate solution (e.g., x/2 approaches zero when its output is repeatedly fed back into it), anyone who has attempted to manage a software project can testify that this does not seem to be true of Hofstadter's Law; if anything, estimates that take Hofstadter's Law into account even partially seem to have an infinite, or at least very large, upper bound. Thus, Hofstadter's Law implies that it is not merely difficult to estimate a project—it is potentially infinitely difficult
A (somewhat joking) rule of thumb introduced by Hofstadter for calculating an approximate time is to double the number and step up to the next higher units. For example, a job estimated at 1 hour can be accomplished in 2 days, while a 3-month project will take you 6 years.
PS: finite difficulty: requires that the extra difficulty decrease quickly enough for the recursive series to converge to a finite value in finite time).
SOA
Service-oriented Architecure is an architectural and design style and paradigm in software engineering. Its primary intent is to align business with IT to create an on-demand or more flexible IT infrastructure. SOA is all about services, reuse, integration and open standards. SOA defines a different approach to software engineering. It involves what is called SOA Governance which is a model which defines the processes and policies for managing and overseeing the SOA structure. It measures how the business's current state is compared to it's business goals. SOA is usually, but not always, implemented using web services.
Monday, January 15, 2007
Give developers their private space!!!
The article is about how giving private space to developers is a major enhancement to any software development organization....hope u enjoy it :D
Check it out!
Check it out!
Saturday, January 13, 2007
Combinations and Permutations
A combination is an unordered collection of unique elements. (An ordered collection is called a permutation.) Given S, the set of all possible unique elements, a combination is a subset of the elements of S. The order of the elements in a combination is not important (two lists with the same elements in different orders are considered to be the same combination). Also, the elements cannot be repeated in a combination (every element appears uniquely once). This is because combinations are defined by the elements contained in them, so the set {1, 1, 1} is the same as {1}. For example, from a 52-card deck any 5 cards can form a valid combination (a hand). The order of the cards doesn't matter and there can be no repetition of cards.
Example of permutations:
1,2,3
1,3,2
2,1,3
2,3,1
...
n! (3 factorial is the number of permutations)
Example of combinations:
Subsets chosen from a larger set of objects in which the order of the items in the subset does not matter. For example, determining how many different committees of four persons could be chosen from a set of nine persons
Example of permutations:
1,2,3
1,3,2
2,1,3
2,3,1
...
n! (3 factorial is the number of permutations)
Example of combinations:
Subsets chosen from a larger set of objects in which the order of the items in the subset does not matter. For example, determining how many different committees of four persons could be chosen from a set of nine persons
Friday, January 12, 2007
Minimax
Suppose the game being played only has a maximum of two possible move per player each turn. The algorithm generates the tree on the right, where the circles represent the moves of the player running the algorithm (maximizing player), and squares represent the moves of the opponent (minimizing player). Because of the limitation of computation resources, as explained above, the tree is limited to a look-ahead of 4 moves.
The algorithm evaluates each leaf node using an heuristic function, obtaining the values shown. The moves where the maximizing player wins are assigned with positive infinity, while the moves that lead to a win of the minimizing player are assigned with negative infinity. At level 3, the algorithm will choose, for each node, the smallest of the child node values, and assign it to that same node (e.g the node on the left will choose the minimum between "10" and "+∞", therefore assigning the value "10" to himself). The next step, in level 2, consists of choosing for each node the largest of the child node values. Once again, the values are assigned to each parent node. The algorithm continues evaluating the maximum and minimum values of the child nodes alternatively until it reaches the root node, where it chooses the move with the l

The algorithm evaluates each leaf node using an heuristic function, obtaining the values shown. The moves where the maximizing player wins are assigned with positive infinity, while the moves that lead to a win of the minimizing player are assigned with negative infinity. At level 3, the algorithm will choose, for each node, the smallest of the child node values, and assign it to that same node (e.g the node on the left will choose the minimum between "10" and "+∞", therefore assigning the value "10" to himself). The next step, in level 2, consists of choosing for each node the largest of the child node values. Once again, the values are assigned to each parent node. The algorithm continues evaluating the maximum and minimum values of the child nodes alternatively until it reaches the root node, where it chooses the move with the l

Informed Search
In an informed search, a heuristic that is specific to the problem is used as a guide. A good heuristic will make an informed search dramatically out-perform any uninformed search.
For example: We can deduce or have access to a certain piece of information that will act as our heuristic function. Building and three eggs problem: If we have knowledge of how high it takes for the egg to break then we can develop a heuristic function that will guide us towards above ten stories. This will narrow down our space and time complexity to find a solution
For example: We can deduce or have access to a certain piece of information that will act as our heuristic function. Building and three eggs problem: If we have knowledge of how high it takes for the egg to break then we can develop a heuristic function that will guide us towards above ten stories. This will narrow down our space and time complexity to find a solution
Coprime numbers
The integers a and b are said to be coprime or relatively prime if they have no common factor other than 1 and −1, or equivalently, if their greatest common divisor is 1.
For example, 6 and 35 are coprime, but 6 and 27 are not because they are both divisible by 3. The number 1 is coprime to every integer; 0 is coprime only to 1 and −1.
A fast way to determine whether two numbers are coprime is given by the Euclidean algorithm
Euclidean algorithm:
Given two natural numbers a and b: check if b is zero; if yes, a is the gcd. If not, repeat the process using (respectively) b, and the remainder after dividing a by b. The algorithm can be naturally expressed using recursion:
function gcd(a, b)
if b = 0 return a
else return gcd(b, a mod b)
or using iteration (more efficient with compilers that don't optimize tail recursion):
function gcd(a, b)
while b ≠ 0
t := b
b := a mod b
a := t
return a
For example, 6 and 35 are coprime, but 6 and 27 are not because they are both divisible by 3. The number 1 is coprime to every integer; 0 is coprime only to 1 and −1.
A fast way to determine whether two numbers are coprime is given by the Euclidean algorithm
Euclidean algorithm:
Given two natural numbers a and b: check if b is zero; if yes, a is the gcd. If not, repeat the process using (respectively) b, and the remainder after dividing a by b. The algorithm can be naturally expressed using recursion:
function gcd(a, b)
if b = 0 return a
else return gcd(b, a mod b)
or using iteration (more efficient with compilers that don't optimize tail recursion):
function gcd(a, b)
while b ≠ 0
t := b
b := a mod b
a := t
return a
Fibonacci sequence
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657...
The birthday paradox
In probability theory, the birthday paradox states that given a group of 23 (or more) randomly chosen people, the probability is more than 50% that at least two of them will have the same birthday. For 60 or more people, the probability is greater than 99%, although it cannot actually be 100% unless there are at least 366 people. This is not a paradox in the sense of leading to a logical contradiction; it is described as a paradox because mathematical truth contradicts naïve intuition. Calculating this probability (and related ones) is the birthday problem. The mathematics behind it has been used to devise a well-known cryptographic attack named the birthday attack.
Thursday, January 11, 2007
Hash tables
Hash tables, a major application for hash functions, enable fast lookup of a data record given its key. For example, keys in an English dictionary would be English words, and their associated records would contain definitions. In this case, the hash function must map alphabetic strings to indexes for the hash table's internal array.
The generally impossible/impractical ideal for a hash table's hash function is to map each key to a unique index (see perfect hashing), because this guarantees access to each data record in the first probe (lookup) in the table.
Hash functions that are truly random with uniform output (including most cryptographic hash functions) are good in that, on average, only one or two probes will be needed (depending on the load factor). Perhaps as important is that excessive collision rates with random hash functions are highly improbable—if not computationally infeasible for an adversary. However, a small, predictable number of collisions is virtually inevitable (see birthday paradox).
In many cases, a heuristic hash function can yield many fewer collisions than a random hash function. Heuristic functions take advantage of regularities in likely sets of keys. For example, one could design a heuristic hash function such that file names such as FILE0000.CHK, FILE0001.CHK, FILE0002.CHK, etc. map to successive indices of the table, meaning that such sequences will not collide. Beating a random hash function on "good" sets of keys usually means performing much worse on "bad" sets of keys, which can arise naturally—not just through attacks. Bad performance of a hash table's hash function means that lookup can degrade to a costly linear search.
Aside from minimizing collisions, the hash function for a hash table should also be fast relative to the cost of retrieving a record in the table, as the goal of minimizing collisions is minimizing the time needed to retrieve a desired record. Consequently, the optimal balance of performance characteristics depends on the application.
One of the most respected hash functions for use in typical hash tables is Bob Jenkins' LOOKUP3 hash function, published in an article in Dr. Dobb's Journal. The hash function performs well as long as there is no adversary, for it is trivially reversible and useless as a cryptographic hash function
Database indexing is an application for hash functions.
The generally impossible/impractical ideal for a hash table's hash function is to map each key to a unique index (see perfect hashing), because this guarantees access to each data record in the first probe (lookup) in the table.
Hash functions that are truly random with uniform output (including most cryptographic hash functions) are good in that, on average, only one or two probes will be needed (depending on the load factor). Perhaps as important is that excessive collision rates with random hash functions are highly improbable—if not computationally infeasible for an adversary. However, a small, predictable number of collisions is virtually inevitable (see birthday paradox).
In many cases, a heuristic hash function can yield many fewer collisions than a random hash function. Heuristic functions take advantage of regularities in likely sets of keys. For example, one could design a heuristic hash function such that file names such as FILE0000.CHK, FILE0001.CHK, FILE0002.CHK, etc. map to successive indices of the table, meaning that such sequences will not collide. Beating a random hash function on "good" sets of keys usually means performing much worse on "bad" sets of keys, which can arise naturally—not just through attacks. Bad performance of a hash table's hash function means that lookup can degrade to a costly linear search.
Aside from minimizing collisions, the hash function for a hash table should also be fast relative to the cost of retrieving a record in the table, as the goal of minimizing collisions is minimizing the time needed to retrieve a desired record. Consequently, the optimal balance of performance characteristics depends on the application.
One of the most respected hash functions for use in typical hash tables is Bob Jenkins' LOOKUP3 hash function, published in an article in Dr. Dobb's Journal. The hash function performs well as long as there is no adversary, for it is trivially reversible and useless as a cryptographic hash function
Database indexing is an application for hash functions.
c++ stack code
// stack.h: header file
class Stack {
int MaxStack;
int EmptyStack;
int top;
char* items;
public:
Stack(int);
~Stack();
void push(char);
char pop();
int empty();
int full();
};
-------------------------------
// stack.cpp: stack functions
#include "stack.h"
Stack::Stack(int size) {
MaxStack = size;
EmptyStack = -1;
top = EmptyStack;
items = new char[MaxStack];
}
Stack::~Stack() {delete[] items;}
void Stack::push(char c) {
items[++top] = c;
}
char Stack::pop() {
return items[top--];
}
int Stack::full() {
return top + 1 == MaxStack;
}
int Stack::empty() {
return top == EmptyStack;
}
class Stack {
int MaxStack;
int EmptyStack;
int top;
char* items;
public:
Stack(int);
~Stack();
void push(char);
char pop();
int empty();
int full();
};
-------------------------------
// stack.cpp: stack functions
#include "stack.h"
Stack::Stack(int size) {
MaxStack = size;
EmptyStack = -1;
top = EmptyStack;
items = new char[MaxStack];
}
Stack::~Stack() {delete[] items;}
void Stack::push(char c) {
items[++top] = c;
}
char Stack::pop() {
return items[top--];
}
int Stack::full() {
return top + 1 == MaxStack;
}
int Stack::empty() {
return top == EmptyStack;
}
Remove duplicates from sorted array (most efficient way)
Since it is a sorted array any duplicates would be next to each other. So start at the beginning and compare each element to it neighbor on its right. If there are no duplicates then you have made n-1 comparisons.
If you find a duplicate you are going to have a hole. Since it is an array an not a link list you will need to move every element down. (You could create a new array if that was allowed.) However you do not just want to start shifting, you can simply mark with a pointer or counter where the hole is and move on to the next comparison. When you get the next non-duplicate you move(copy) that element into the hole and increment your hole counter by 1.
So here is some C code that will do just that.
bool RemoveDuplicates(int array[], int iSize){
//validation: if array is empty, null, just one element
if(iSize < 1) return false;
if(array == NULL) return false;
if(iSize == 1) return true;
int left_compare = 0;
int right_compare = 1;
bool start_move = false;
int hole = iSize;
for( ; right_comp
if(array[left_comp] == array[right_comp]){
if(!start_move){
start_move = true;
hole = right_comp;
}
}
else if(start_move){
array[hole++] = array[right_comp];
}
}
//fill up the rest of the elements with zeros as they are no longer needed. this is //needed
//in the case where the right_comp comes to the end and there are still holes in //the array
for(;hole
}
return true;
}
void main(){
int array[] = {1,1,1,1,1,1,1,1,2,2,4,5,7,8,8,9,9,10,11,11,12,13,14};
int iSize = sizeof(array)
int i;
if(!bRemoveDuplicates(array,iSize))
{
cout<
cin>>i;
}
If you find a duplicate you are going to have a hole. Since it is an array an not a link list you will need to move every element down. (You could create a new array if that was allowed.) However you do not just want to start shifting, you can simply mark with a pointer or counter where the hole is and move on to the next comparison. When you get the next non-duplicate you move(copy) that element into the hole and increment your hole counter by 1.
So here is some C code that will do just that.
bool RemoveDuplicates(int array[], int iSize){
//validation: if array is empty, null, just one element
if(iSize < 1) return false;
if(array == NULL) return false;
if(iSize == 1) return true;
int left_compare = 0;
int right_compare = 1;
bool start_move = false;
int hole = iSize;
for( ; right_comp
if(array[left_comp] == array[right_comp]){
if(!start_move){
start_move = true;
hole = right_comp;
}
}
else if(start_move){
array[hole++] = array[right_comp];
}
}
//fill up the rest of the elements with zeros as they are no longer needed. this is //needed
//in the case where the right_comp comes to the end and there are still holes in //the array
for(;hole
}
return true;
}
void main(){
int array[] = {1,1,1,1,1,1,1,1,2,2,4,5,7,8,8,9,9,10,11,11,12,13,14};
int iSize = sizeof(array)
int i;
if(!bRemoveDuplicates(array,iSize))
{
cout<
cin>>i;
}
Tuesday, January 9, 2007
PSO
PSO is Particle Swarm Optimization. A simple but powerful artificial intelligence field. In its simplest form, PSO is composed of a problem space with a certain solution or best position in it. Particles are scattered across this problem space. The particles each have a local fitness value according to their positions relative to the global best position. According to a simple algorithm displayed below, the particles evolve and begin to converge upon the solution to the problem in the problem space.
Algorithm:
Let there be n particles, each with associated positions and velocities
and velocities  ,
, 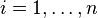 . Let
. Let  be the current best position of each particle and let
be the current best position of each particle and let  be the global best.
be the global best.
Algorithm:
Let there be n particles, each with associated positions
and velocities , . Let be the current best position of each particle and let be the global best. - Initialize
 and
and 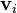 for all i. One common choice is to take
for all i. One common choice is to take ![\mathbf{x}_{ij} \in U[a_j, b_j]](http://upload.wikimedia.org/math/4/0/7/4072746cf6ddf9f4289fe6cf79f00337.png) and
and  for all i and
for all i and  , where aj,bj are the limits of the search domain in each dimension.
, where aj,bj are the limits of the search domain in each dimension.  and
and  .
.
- While not converged:
- For
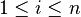 :
:  .
. .
.- If
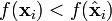 , .
, . - If
 ,
,  .
.
- For
Note the following about the above algorithm:
- ω is an inertial constant. Good values are usually slightly less than 1.
- c1 and c2 are constants that say how much the particle is directed towards good positions. They represent a "cognitive" and a "social" component, respectively, in that they affect how much the particle's personal best and the global best (respectively) influence its movement. Usually, we take
 but this need not be the case.
but this need not be the case.  are two random vectors with each compenent generally a uniform random number between 0 and 1.
are two random vectors with each compenent generally a uniform random number between 0 and 1. operator indicates element-by-element multiplication i.e. the Hadamard matrix multiplication operator.
operator indicates element-by-element multiplication i.e. the Hadamard matrix multiplication operator.
Monday, January 8, 2007
C++ string manipulation
Find a string within a string
Searching a string within another string is a breeze with std::string. The Standard Library defines several specialized overloaded versions of string::find() that take const string&, const char *, or just char as a sought-after value (the substring). Here, I will only show how to use the first version for locating a string object within another string objects; implementing other versions should be a cinch.
string verse="Franco's rain in Spain";
string sought = "rain";
int pos=verse.find(sought); // pos=9
Substring Replacement
Suppose you want to replace the sought-after value with another substring, just as your word processor does when you use "search and replace." The replace() function (which also has several overloaded versions) does the trick. The canonical version takes three arguments: the position, or offset into which the replacement string should be written; the length of the substring to be replaced; and an overriding string. For example, the following code corrects the typo in phrase by replacing "rain" with "reign":
phrase.replace(pos, sought.size(), replacement);
cout<
Searching a string within another string is a breeze with std::string. The Standard Library defines several specialized overloaded versions of string::find() that take const string&, const char *, or just char as a sought-after value (the substring). Here, I will only show how to use the first version for locating a string object within another string objects; implementing other versions should be a cinch.
string verse="Franco's rain in Spain";
string sought = "rain";
int pos=verse.find(sought); // pos=9
Substring Replacement
Suppose you want to replace the sought-after value with another substring, just as your word processor does when you use "search and replace." The replace() function (which also has several overloaded versions) does the trick. The canonical version takes three arguments: the position, or offset into which the replacement string should be written; the length of the substring to be replaced; and an overriding string. For example, the following code corrects the typo in phrase by replacing "rain" with "reign":
phrase.replace(pos, sought.size(), replacement);
cout<
C functions
sprintf()
#include
int sprintf( char *buffer, const char *format, ... );
e.g: char result[100];
int num=24;
sprintf( result, "%d", num );
scanf()
#include
int main(void) {
int n;
while (scanf("%d", &n) > 0)
printf ("%d\n", n);
return 0;
}
f - format
A wise man once said...
- "Computer Science is no more about computers than astronomy is about telescopes"
- - E. W. Dijkstra
Friday, January 5, 2007
Microkernel and Monolithic Kernel
A microkernel is a minimal system kernel providing only basic operating system services (system calls), while other services (commonly provided by kernels) are provided by user-space programs called servers. Microkernels provide services such as address space management, thread management, and IPC, but not netoworking or display for example.
Advantages of the microkernel approach to system design: (a) adding new service does not require modifying the kernel, (b) it is more secure as more operations are done in user mode than in kernel mode, (c) a simpler kernel design and functionality typically results in a more reliable operating system.
A monolithic kernel is a kernel architecture where the entire kernel is run in kernel space in supervisor mode. In common with other architectures, the kernel defines a high-level virtual interface over computer hardware, with a set of primitives or system calls to implement operating system services such as process management, concurrency, and memory management in one or more modules.
Even if every module servicing these operations is separate from the whole, the code integration is very tight and difficult to do correctly, and, since all the modules run in the same address space, a bug in one module can bring down the whole system. However, when the implementation is complete and trustworthy, the tight internal integration of components allows the low-level features of the underlying system to be effectively utilized, making a good monolithic kernel highly efficient. In a monolithic kernel, all the systems such as the filesystem management run in an area called the kernel mode.
Source: Wikipedia.org
Semaphores and Monitors
Semaphores:
A semaphore is a protected variable (or ADT) and constitutes the classic method for restricting access to shared resources (e.g. storage) in a multiprogramming environment. They were invented by Edsger Dijkstra
The value of the semaphore is initialized to the number of equivalent shared resources it is implemented to control. In the special case where there is a single equivalent shared resource, the semaphore is called a binary semaphore.
Semaphores are the classic solution to the dining philosophers problem, although they do not prevent all deadlocks.
The simplest kind of semaphore is the "binary semaphore," used to control access to a single resource. It is essentially the same as a mutex. It is always initialized with the value 1. When the resource is in use, the accessing thread calls P(S) to decrease this value to 0, and restores it to 1 with the V operation when the resource is ready to be freed (number represents how many processes can have access).
only one process at a time is allowed "inside'' the monitor where "inside'' means a call of an operation in the monitor is in progress or accepted
Two "life simplifying'' assumptions regarding condition variables
- the signaler must exit the monitor immediately after signaling by executing a return statement so that nothing can change before the signaled process wakes up
- the signaled process is given priority to proceed inside the monitor over those processes waiting to enter the monitor through an operation call so that in this way the signaled process finds the condition still true when it resumes
Monitors can be implemented with semaphores and vice versa
You use monitors in applications, not in operating systems.
to be continued ...
The Josephus problem
The Josephus problem is a theoretical problem occurring in computer science and mathematics. There are n people standing in a circle waiting to be executed. After the first man is executed, k − 1 people are skipped and the k-th man is executed. Then again, k − 1 people are skipped and the k-th man is executed. The elimination proceeds around the circle (which is becoming smaller and smaller as the executed people are removed), until only the last man remains, who is given freedom.
The task is to choose the place in the initial circle so that you survive (are the last one remaining), given n and k.
Sorting algorithms
There are many sorting algorithms. I will list the most common and the not so known ones and provide links to read to understand them:
1. Bubble sort
2. Insertion sort
3. Shell sort - shell sort
4. Merge sort
5. Heapsort
6. Quicksort
7. Radix sort - radix sort
8. Counting sort - counting sort
There are many others, like: bucket sort , pigeonhole sort...
Wikipedia has a very good definition for each of these sorting algorithms. Just goto sorting algorithms
1. Bubble sort
2. Insertion sort
3. Shell sort - shell sort
4. Merge sort
5. Heapsort
6. Quicksort
7. Radix sort - radix sort
8. Counting sort - counting sort
There are many others, like: bucket sort , pigeonhole sort...
Wikipedia has a very good definition for each of these sorting algorithms. Just goto sorting algorithms
Hello
This, I hope will be my technical blog from now on. Ill post technological information as I venture into tech-land. This will be a kind of self-study program for myself where I'll investigate topics that are new to me and blog my reports on them. Hope I enjoy this and write a lot and I hope someone out there finds this information useful!!!
Subscribe to:
Posts (Atom)